vLLM 部署 Qwen2.5-VL-72B
Openbayes 部署 Qwen2.5-VL¶
- 启动容器
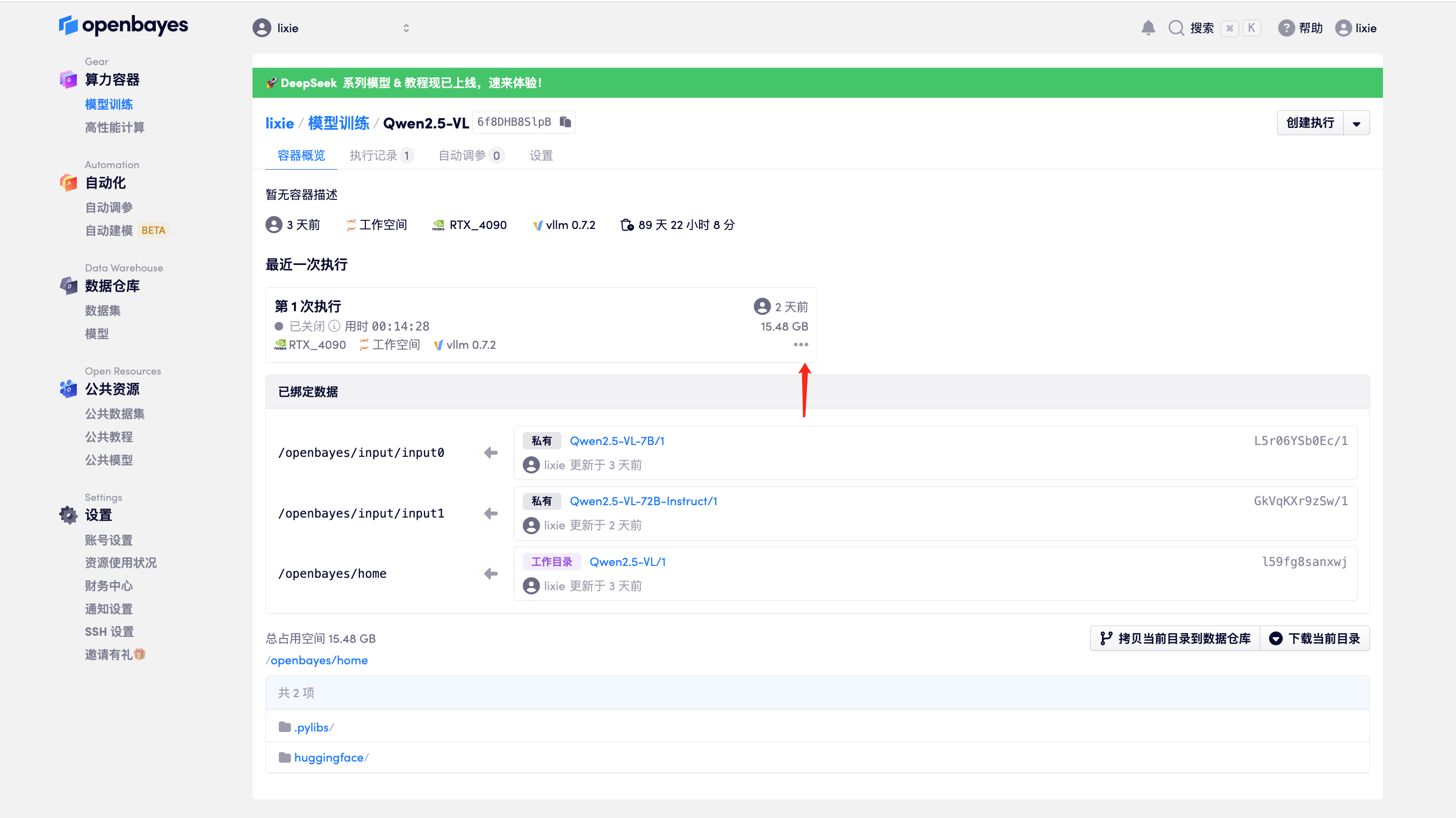
- 配置说明
- 这个 7B 的模型不是很大,一个 4090/a6000 跑起来足够了
安装依赖软件
pip install git+https://github.com/huggingface/transformers@f3f6c86582611976e72be054675e2bf0abb5f775
pip install accelerate
pip install qwen-vl-utils
pip install 'vllm>0.7.2'
温馨提示:
由于我们是自己在本地 「download」的模型,里面有些模型的位置路径,需要替换成自己的
启动 OpenAI API 服务¶
vllm serve Qwen/Qwen2.5-VL-7B-Instruct --port 8000 --host 0.0.0.0 --dtype bfloat16 --limit-mm-per-prompt image=5,video=5
debug¶
Vllm 参数含义
vllm serve /openbayes/input/input0/Qwen2.5-VL-72B-Instruct \ # 指定模型的绝对路径
--port 8080 \ # 设置API服务监听的端口号,默认为8080
--host 0.0.0.0 \ # 指定服务监听的主机地址,0.0.0.0表示监听所有可用的网络接口
--dtype bfloat16 \ # 设置模型使用的数据类型为bfloat16,用于提高模型的计算效率
--tensor-parallel-size 4 \ # 设置张量并行计算的GPU数量为4,要求同时使用4张GPU进行并行计算
--max-model-len 16384 \ # 设置模型的最大长度为16384,用于限制模型处理的输入数据大小
--gpu-memory-utilization 0.95 \ # 设置GPU内存利用率为0.95,用于控制模型对GPU资源的使用
--block-size 32 \ # 设置数据块的大小为32,用于控制模型处理数据的粒度
--extra-params "multimodal_config={'max_images':5, 'max_videos':5}" \ # 设置多模态配置,限制每个提示最多包含5张图片和5个视频
测试¶
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/openbayes/input/input0/Qwen2.5-VL-72B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://barry-boy-1311671045.cos.ap-beijing.myqcloud.com/blog/guilin.png"}},
{"type": "text", "text": "这是什么地方"}
]}
]
}'
文章参考¶
- https://github.com/QwenLM/Qwen2.5-VL/